Instana Karmaşık Sorguları İşlem Süresinde Nasıl Optimize Ediyor?
Instana, dashboard’larda ve Unbounded Analytics’te doğru ve anlık uygulama izleme ölçümleri sağlamayı amaçlar. Bu ölçümler, gözlem altındaki sistemlerden toplanan milyonlarca isteğe (call) göre hesaplanır. İstekler columnar bir database olan Clickhouse’da saklanır ve her isteğe ait yüzlerce tag bulunur.
Bu verilerin sorgulanmasını hızlandırmak için çeşitli teknikler kullanıyoruz. Bunlardan en önemlisi materialized views (MV) kullanılmasıdır. Buradaki amaç, service.name, endpoint.name, http.status gibi en sık kullanılan tagleri seçmek ve bu taglerin üzerindeki metrikleri, farklı boyutlardaki gruplar içinde önceden toplamaktır. MV, orijinal tablodan çok daha az veri içerir, bu nedenle görünümden okumak, filtrelemek ve toplamak çok daha hızlıdır.
Ancak, bu yaklaşımın bir sınırlaması vardır. MV’ye dahil edilemeyen 2 tür tag bulunur. Bu nedenle, bu taglere göre filtreleme veya gruplama yapan sorgular optimize edilemez:
1. Çok yüksek kardinaliteye sahip tag
MV’ye http.url gibi taglerin dahil edilmesi, MV’deki satır sayısını artıracaktır. Örneğin, MV’de yalnızca endpoint.name eklersek, grup boyutu 1 dakika ise endpoint /api/users/{id} dakikada yalnızca 1 satıra sahip olur. Ancak, ek olarak http.path eklersek ve endpoint, /api/users/123 gibi yüzlerce farklı yolla istek alırsa, her benzersiz yol, MV’de yeni bir satır oluşturur.
2. Kullanıcı tarafından tanımlanan custom key value pair tag
Kullanıcılar bir aracıya (agent.tag), SDK üzerinden bir isteğe (call.tag), bir docker container’a (docker.label) özel tagler ekleyebilir veya özel bir HTTP başlığı (call.http.header) tanımlayabilir. Her tag’e ait özel bir key ve value vardır, ör. agent.tag.env=prod, docker.label.version=1.0 gibi. Key’ler dinamiktir ve Instana tarafından bilinmez, dolayısıyla bu sütunların üzerinde statik bir MV oluşturamayız.
Bu tagleri kullanarak sorguların gecikmesini optimize edecek bir çözüm bulmamız gerekiyor.
Çözüm
Instana’nın sağladığı çözüm, MV’ler tarafından optimize edilemeyen karmaşık sorguları otomatik olarak tespit etmek, bunları önceden hesaplanmış filtreler (precomputed filters) olarak kaydetmek ve işlem süresi boyunca bu filtrelerle eşleşen tag isteklerini yapmaktır. Asıl amaç, karmaşıklığı sorgu zamanından işlem süresine taşımaktır. Bu çözüm arama işleme sırasında filtreleme ve toplama iş yükünü zamana daha iyi dağıtmaya olanak tanır. Yük arttığında, proses komponentini ölçeklendirmek database’den daha kolay ve daha az maliyetlidir.
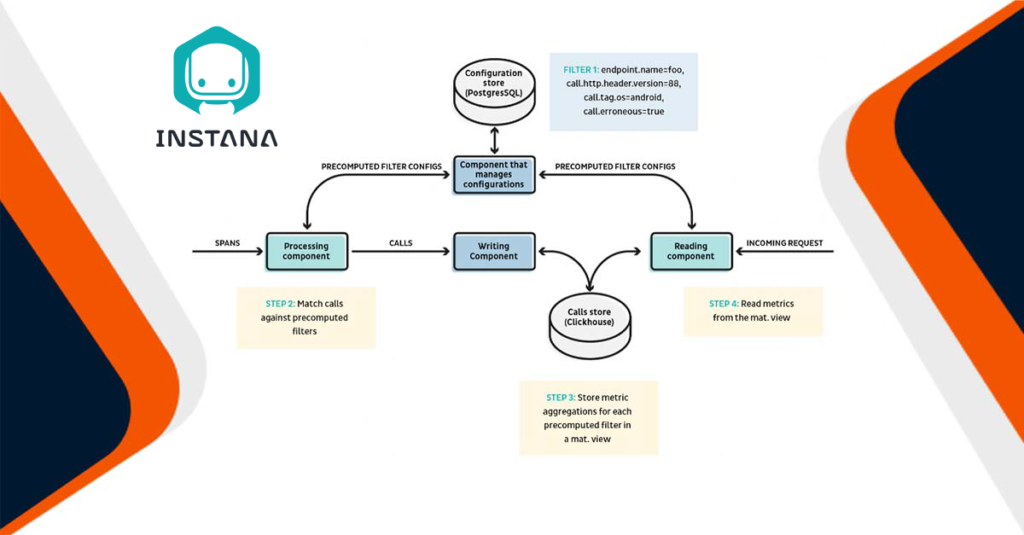
Genel mimari aşağıdaki gibi görünür:
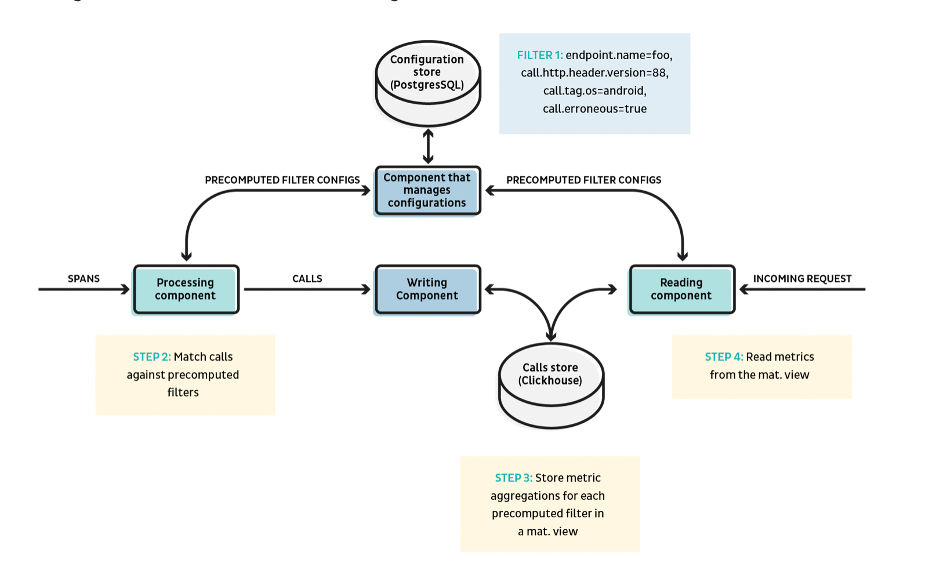
Adım 1:
Reading component(Okuma bileşeni), karmaşık sorguları algılar ve önceden hesaplanmış bir filtre olarak kaydeder ve bunları paylaşılan bir database’e gönderir. Önceden hesaplanmış bir filtre temel olarak bir key ile çağrılardaki taglere sahip karmaşık bir filtreleme arasında eşleme yapar.
Bir örnekle anlatacak olursak, filter1: endpoint.name=foo AND call.http.header.version=88 AND call.tag.os=android AND call.erroneous=true, ek olarak oluşturma zamanı veya son isabet zamanı gibi bazı meta veriler.
Adım 2:
Processing component (İşlem bileşeni), paylaşılan veri tabanından önceden hesaplanan filtreleri okur. Gelen her istek, tüm kayıtlı önceden hesaplanmış filtrelerle eşleştirilecektir. Bir eşleşme varsa istek, filtre kimliğiyle taglenir. Bir arama, birden çok filtreyle eşleşiyorsa birden çok kimlikle taglenebilir.
Adım 3:
İstekler (call), precomputed_filter_ids Array (String) ek sütunuyla Clickhouse’ta depolanır. Daha sonra, istekleri önceden hesaplanmış her bir filtre kimliğine göre gruplandıran MV oluştururuz. ID, görünüm tablosunun birincil (primary) key ve sıralama (sorting) key’i olacak ve ardından bucket zaman damgasına (timestamp) sahip olacaktır, bu nedenle ID tarafından filtrelenen görünümün sorgulanması son derece hızlıdır.
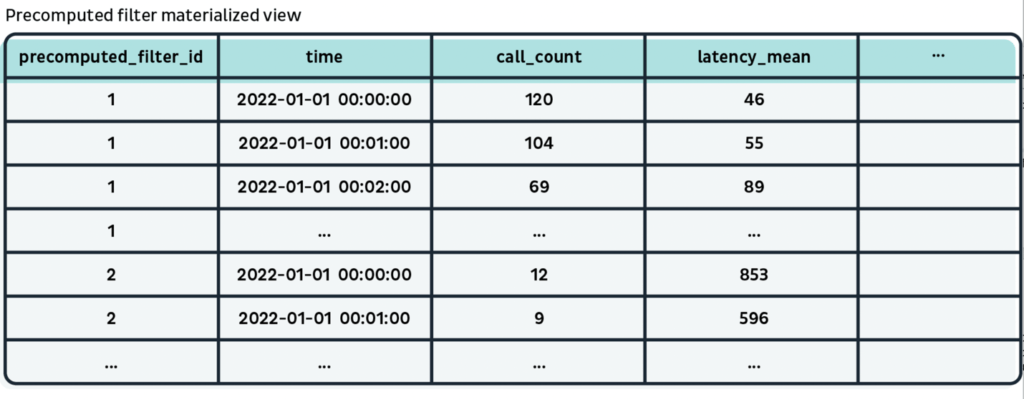
Adım 4:
Okuma bileşeni (reading component), karmaşık bir sorguyu precomputed_filter.id = xxx‘e dönüştürebilir ve karmaşık sorguyla eşleşen çağrıların metriklerini döndürmek için MV sorgulayabilir.
Örnek Pseuode Sorgusu:
SELECT SUM(call_count)
FROM precomputed_filter_view
WHERE time > toDateTime(‘2022-06-01 00:00:00’)
AND time < toDateTime(‘2022-06-01 12:00:00’)
AND precomputed_filter_id = ‘1’
Gruplamayı Nasıl Yaparız?
precomputed_filter.id = xxx yalnızca filtreleme bölümünü işler, sorgu, endpoint.name gibi bir etiketle gruplandırılmış metrikler isterse, bunu ek adımlarla halletmemiz gerekir.
İşlem sırasında, bir çağrı filtreyle eşleşirse, çağrıdan endpoint.name gruplama tag’inin değerini çıkarmamız ve ayrıca bu tag’i ek bir sütunda saklamamız gerekir. Sütun ayrıca, sıralama anahtarındaki precomputed_filter_id ve time sütunlarından sonra yerleştirilen MV’ye dahil edilecektir.
Örnek Pseuode Sorgusu:
SELECT precomputed_filter_group, SUM(call_count)
FROM precomputed_filter_view
WHERE time > toDateTime(‘2022-06-01 00:00:00’)
AND time < toDateTime(‘2022-06-01 12:00:00’)
AND precomputed_filter_id = ‘1’
GROUP BY precomputed_filter_group
Sonuç
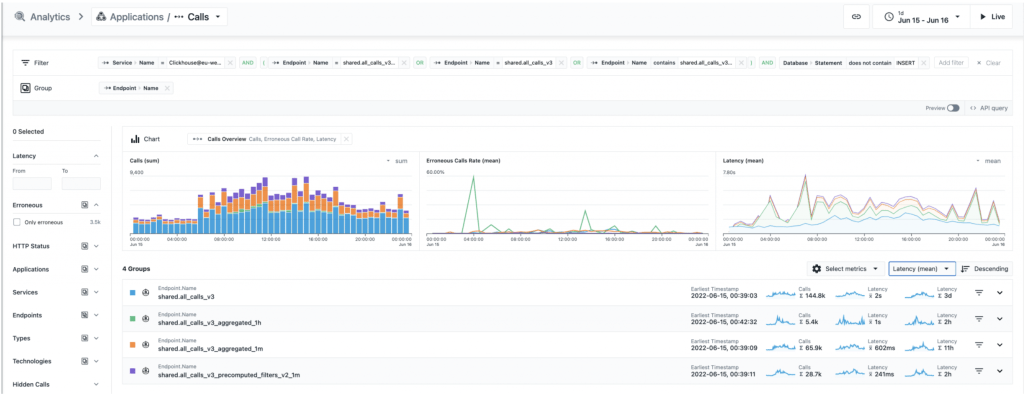
Bu görselde, Avrupa bölgesinde Instana müşterilerinin bir gün boyunca yaptığı sorguların, farklı tablo ve görünümlere göre ayrılmış, çok ayrıntılı bir analizi yer almaktadır. Önceden hesaplanan filtre ile, sorguların, orijinal aramalar tablosuna göre neredeyse 10 kat daha hızlı olduğunu ve aynı bucket size (1dk) için optimize edilmiş bir sorgudan 3 kat daha hızlı olduğunu görebiliriz.
Sınırlamalar ve Gelecekteki İyileştirmeler
En büyük limit, bir sorgunun ancak önceden hesaplanmış bir filtre olarak ilk kez kaydedildikten sonra optimize edilebilmesidir. Kullanıcıların düzenli olarak yaptığı yinelenen sorgular için iyi çalışır. Bununla birlikte, bir kullanıcı Unbounded Analytics’te son bir gün içinde ilk kez geçici bir sorgu çalıştırırsa, optimizasyon hemen devreye giremez. İşlem hattındaki yükü sınırlamak için, belirli bir süre kullanılmadığında önceden hesaplanan bir filtreyi de devre dışı bırakırız.
Bazı karmaşık sorgular, özel bir panoda veya alarm içerisinde yapılandırılırsa tahmin edilebilir. Bu durumlarda, önceden hesaplanmış filtreler oluşturmak için yapılandırmayı kullanabiliriz; böylece kullanıcılar, özel panoyu açsalar veya ilk kez bir uyarıdan Unbounded Analytics’e atlasalar bile metrikleri ve grafikleri hızlı bir şekilde görebilirler.
Instana hakkında detaylı bilgi almak için bizimle iletişime geçin!
