
Your IT Infrastructure Never Sleeps: 24/7 Smart Monitoring
Your IT Infrastructure Never Sleeps: 24/7 Smart Monitoring! NOC & IT Operations & Smart Monitoring AI-supported automation, proactive alarm management, and L0–L2 techni
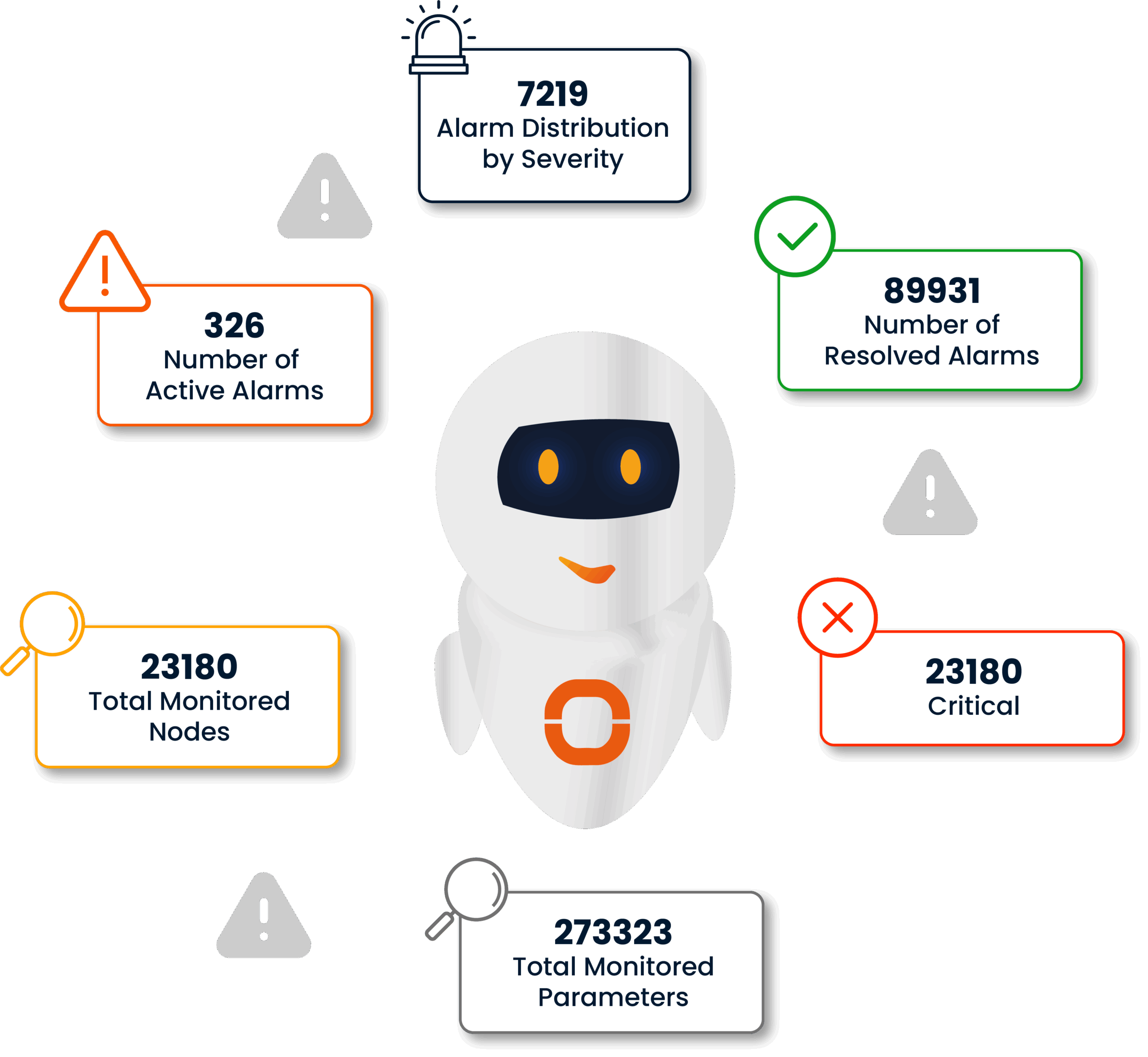
ODYA Automated NOC continuously monitors and analyzes all layers of your IT environment 24/7. It ensures uninterrupted tracking of components at every level of your infrastructure, enabling immediate intervention in case of potential issues.
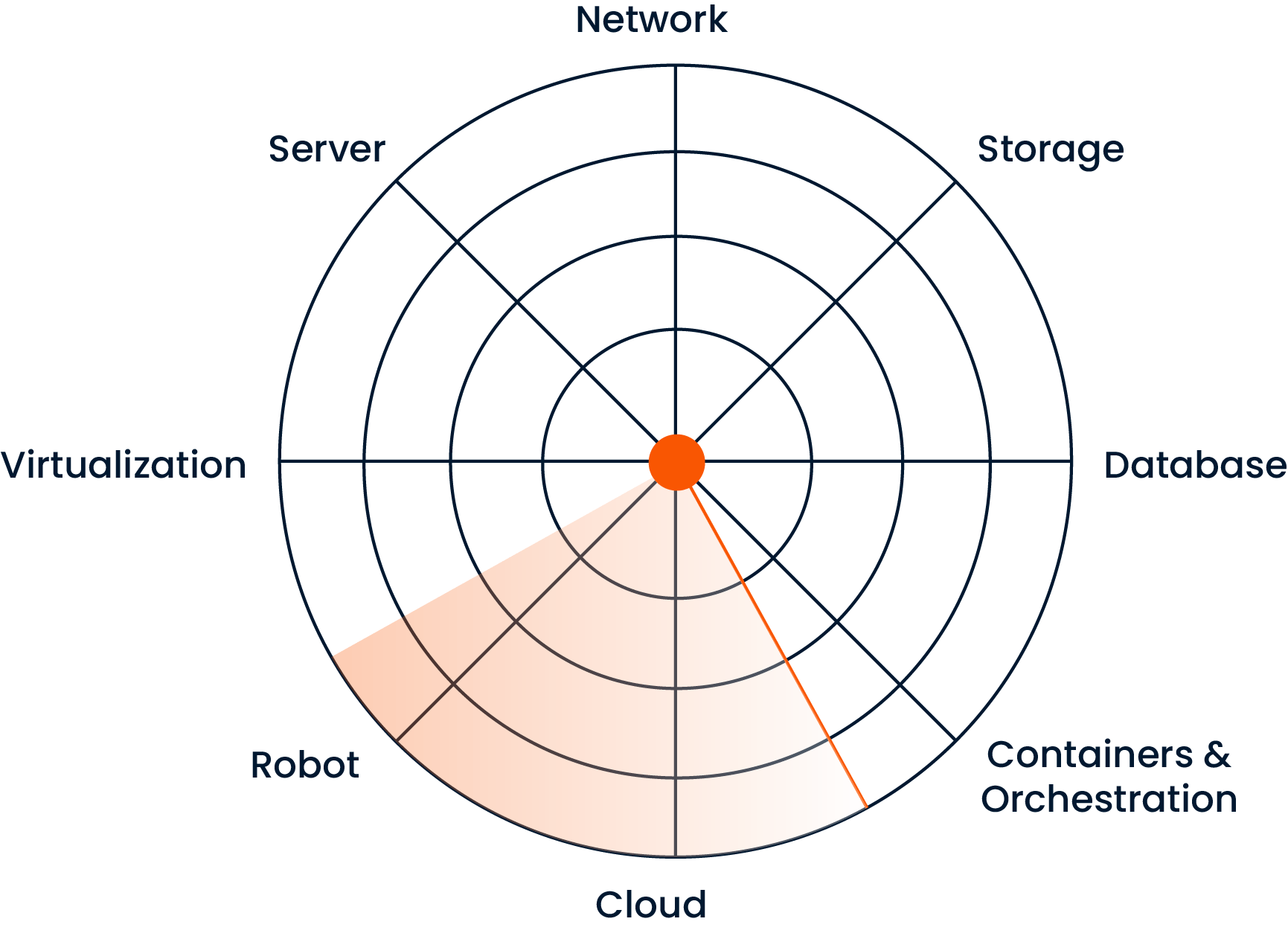
By automatically converting alerts from monitoring systems into actionable notifications, it eliminates the risk of missed incidents. When ODYA Automated NOC detects an event, it promptly notifies relevant teams via written alerts or call-based notifications through the platform.
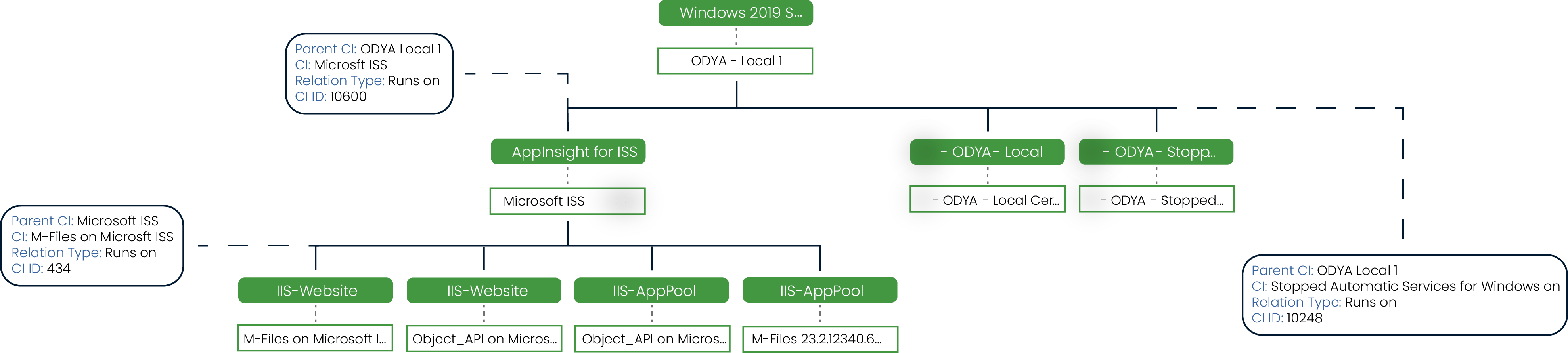
ODYA Automated NOC automatically discovers your IT assets, maps their interdependencies, and continuously keeps the CMDB up to date—ensuring incidents are managed with the right context and accuracy.
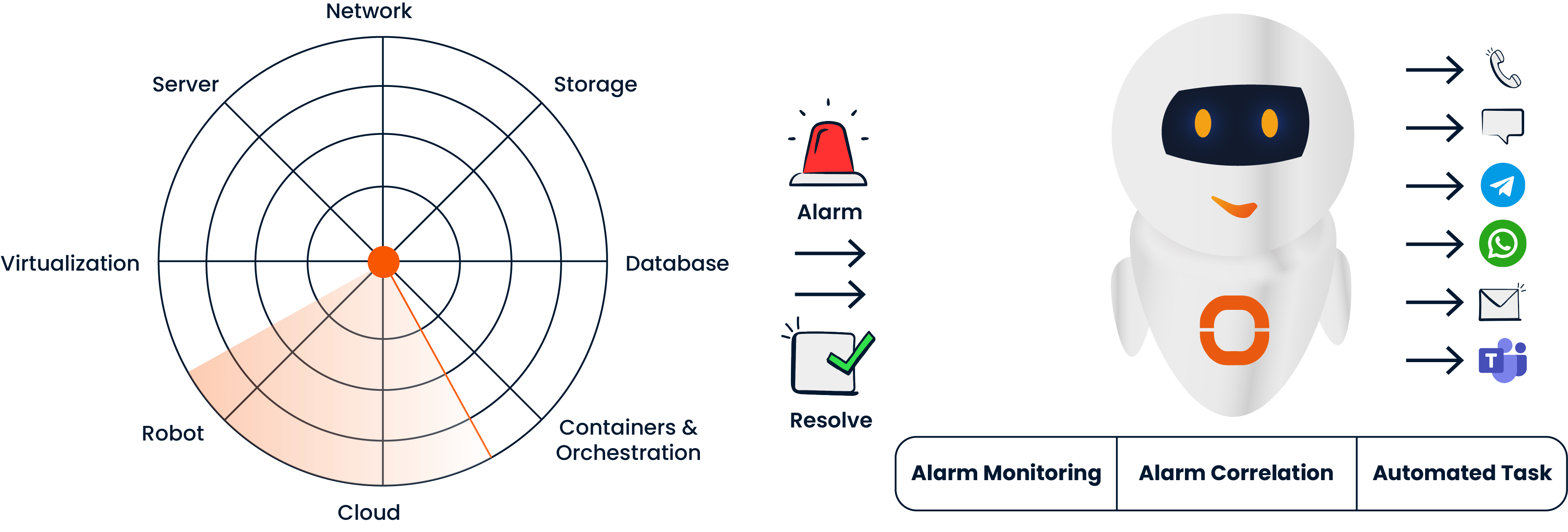
Utilizing predefined rules and AI-driven scenarios, ODYA Automated NOC automates incident response actions. When previously encountered and documented “known issues” occur, the system instantly applies the corresponding “known solutions.”

ODYA Automated NOC aggregates, analyzes, and generates insights from large volumes of logs, metrics, event records, and performance data collected from various systems, providing a single source of truth for your IT operations.
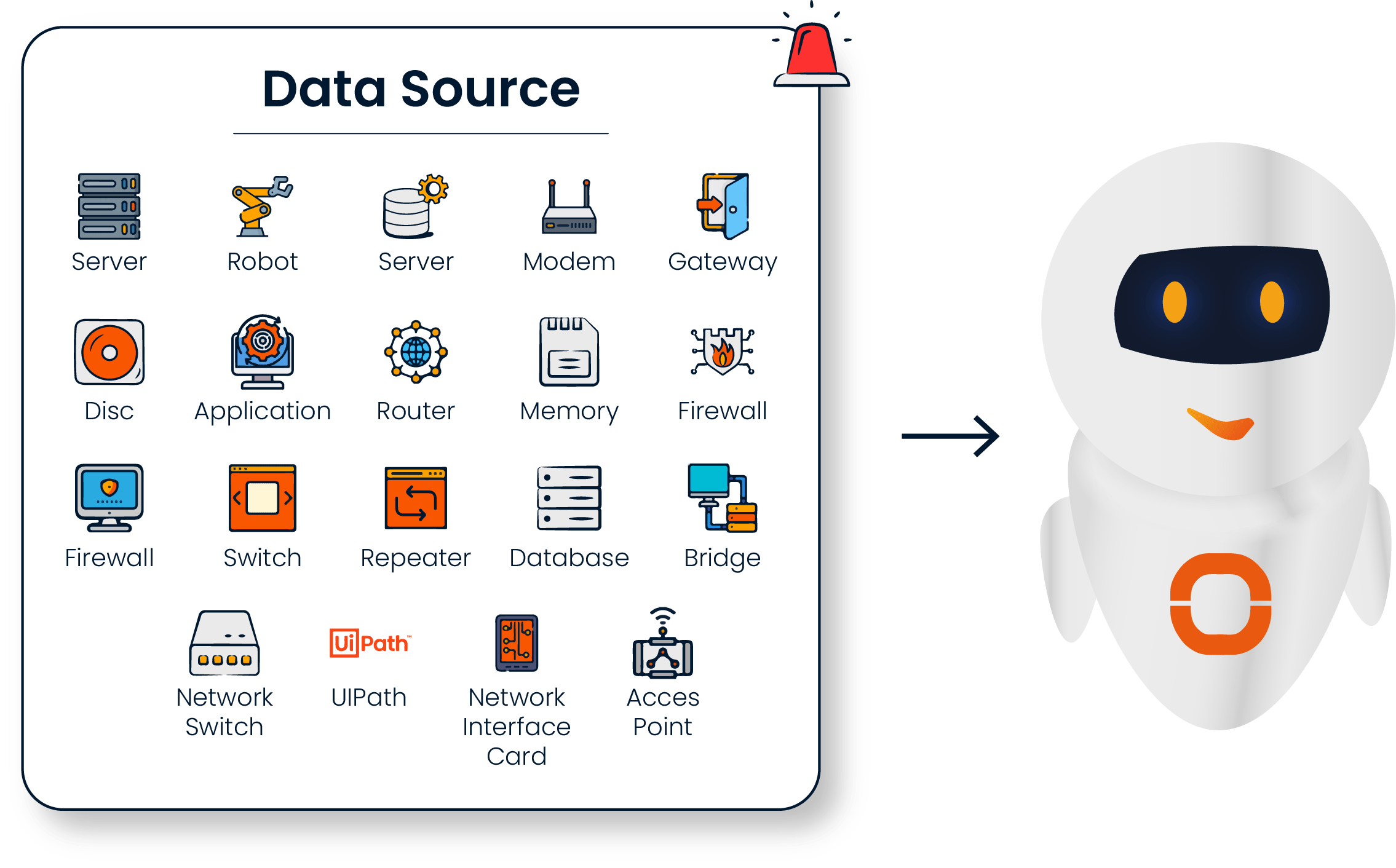
Through proactive monitoring and advanced root cause analysis capabilities, it not only identifies issues but also prevents recurring or similar incidents in the future.

Within 24/7 NOC services, reporting and documentation represent a structured and comprehensive process that underpins incident management, SLA monitoring, performance evaluation, CI health, and effective knowledge sharing. This function is essential for maintaining operational transparency, providing a clear overview of system status, and facilitating thorough root cause analysis of potential issues.
Your IT Infrastructure Never Sleeps: 24/7 Smart Monitoring! NOC & IT Operations & Smart Monitoring AI-supported automation, proactive alarm management, and L0–L2 techni
What Are the Main Types of IT Anomalies? How Does ODYA Automated NOC Detect and Resolve Them? Table of Contents Alert management in modern IT infrastructures has long surpas

Monitoring and Alarm Management: No Longer Reactive, But Smart and Proactive ! Table of Contents Finding a real incident in the nightly flood of alerts is like searching for

What Is Ticket Enrichment? How Smart Ticket Enrichment Helps Problem Management? Table of Contents When a support ticket arrives and contains only a few lines of text, your

24/7 Incident Detection and Reporting: Why is it critical? İçindekiler Continuous monitoring in modern IT infrastructures is no longer a luxury, but a necessity. With ODYA
How Does Tool Sprawl Slow Down NOC Operations? Table of Contents Monitoring tool sprawl has become one of the most critical yet often overlooked challenges in modern IT oper

From On-Call Management to Playbook Automation: The Strategic Shift in IT Table of Contents Setting up an on-call management rotation is a starting point not a destination.

Noise Reduction with Alarm Correlation One of the greatest challenges in modern IT infrastructures is getting lost in the excessive number of alarms generated by systems. Every com

Without Event Correlation, Simply Silencing the Alarm Is Not Enough! İçindekiler Alarm correlation reduces alarm noise. Event correlation, on the other hand, identifies th

+90 216 577 5320

info@odya.com.tr

Barbaros Mah. Begonya Sok. No: 3 NİDA Kule Kuzey Kat: 12 Ofis:133, 34746 Ataşehir/İstanbul
BİRUNİ Teknopark – Kazlıçeşme Mah. 245.Sok. No:5 Zeytinburnu/İstanbul