Veri Anonimleştirme Aracı: KVKK & GDPR Uyumlu Hassas Veri Koruma!
Günümüz dijital çağında kurumlar, artan veri hacmi ve sıkılaşan regülasyonlarla birlikte kişisel verilerin korunması konusunda daha titiz davranmak zorunda. Test ortamlarından analiz süreçlerine, raporlamadan eğitim içeriklerine kadar birçok alanda gerçek verilerle çalışmak risk yaratabilir. İşte tam bu noktada SPIDYA’nın Veri Anonimleştirme Aracı devreye giriyor: kurumların hassas verileri güvenle paylaşmasını, analiz etmesini ve kullanmasını sağlayan güçlü bir yapay zekâ çözümü sunuyor.
İçindekiler
Veri Anonimleştirme Nedir?
Veri anonimleştirme, metin veya dosyalarda yer alan kişisel tanımlayıcı bilgilerin (PII) ve diğer hassas verilerin tespit edilip kalıcı olarak maskelenmesi işlemidir. Bu süreç, verilerin orijinal hallerinin korunmasını engeller ve veri sahibinin kimliğinin ifşa edilmesini önler — böylece KVKK, GDPR gibi düzenlemelere tam uyum sağlayan bir gizlilik seviyesi elde edilir.
SPIDYA’nın Veri Anonimleştirme Aracının Özellikleri
AI Destekli Otomatik Tespit
SPIDYA’nın aracı, gelişmiş yapay zekâ modelleriyle metin içerisindeki hassas veri türlerini otomatik olarak algılar — isimler, TCKN, e-posta adresleri, IP adresleri, IBAN gibi birçok kritik veri tipi anında tanımlanır.
Akıllı Maskeleme
Aracın en güçlü yönlerinden biri, aynı veri tekrarlandığında tutarlı şekilde aynı maskeleme etiketini kullanmasıdır. Bu sayede anonimleştirilmiş veri, bağlamını ve ilişkileri korurken hâlâ gizliliği sağlar.
Çeşitli Veri Tiplerini Destekler
– Kişisel Bilgiler: İsim, doğum tarihi, yaş, cinsiyet
– Kimlik Verileri: TCKN, pasaport, ehliyet
– İletişim: E-posta, telefon, adres
– Finansal Veriler: IBAN, banka hesap numarası, kredi kartı
– Dijital Veriler: IP, MAC, URL, kullanıcı adı
– Kurumsal Bilgiler: Şirket/organizasyon isimleri, pozisyonlar
– Konum Verileri: GPS, sokak adresleri
– Diğer Hassas Tanımlayıcılar gibi geniş kapsamlı veri türleri desteklenir.
Neden Veri Anonimleştirme Kullanılmalı?
Mevzuata Uyum: KVKK, GDPR ve benzeri düzenlemelerle uyumlu veri süreçleri oluşturmak kritik. SPIDYA aracı bu uyumu kolaylaştırır.
Güvenli Paylaşım: Yasal veya operasyonel sebeplerle veri paylaşılması gerektiğinde, anonimleştirme kişisel bilgi riskini ortadan kaldırır.
Veri Analizi ve Test: Ürün ekipleri ve analistler gerçek verilerle çalışmadan önce anonimleştirilmiş veri setleri üzerinde güvenle çalışabilirler.
Veri Anonimleştirme ile Maskeleme Arasındaki Fark Nedir?
Veri anonimleştirme ve veri maskeleme kavramları sıklıkla birbirinin yerine kullanılsa da, teknik olarak farklı amaçlara hizmet eder.
Veri maskeleme (data masking), hassas verinin yalnızca görüntüsünün gizlenmesini ifade eder. Örneğin bir kredi kartı numarasının ilk ve son hanelerinin gösterilip ortasının yıldızlanması maskeleme örneğidir. Bu yaklaşım, belirli senaryolarda yeterli olabilir; ancak çoğu zaman verinin orijinal haline geri dönülebilmesi mümkündür.
Veri anonimleştirme (data anonymization) ise verinin, veri sahibiyle ilişkilendirilemeyecek şekilde hedefler. Bu sayede anonimleştirilen veri, artık kişisel veri kapsamından çıkar ve kimlik tespiti yapılamaz hale gelir. KVKK ve GDPR gibi regülasyonlar açısından asıl güvenli yöntem anonimleştirmedir.
SPIDYA’nın Anonimleştirme Aracı, yalnızca yüzeysel maskeleme yapmakla kalmaz; hassas verileri bağlamı korunacak şekilde anonimleştirir. Aynı kişi veya bilgi metin içinde tekrar ediyorsa, sistem bunları tutarlı biçimde aynı etiketle anonimleştirir. Böylece verinin ilişkisel yapısı bozulmazken, kişisel bilgiler tamamen koruma altına alınmış olur.
Bu yaklaşım sayesinde kurumlar, test, analiz, raporlama ve eğitim gibi süreçlerde gerçek veriye ihtiyaç duymadan, güvenli ve regülasyonlara uyumlu veri setleriyle çalışabilir.
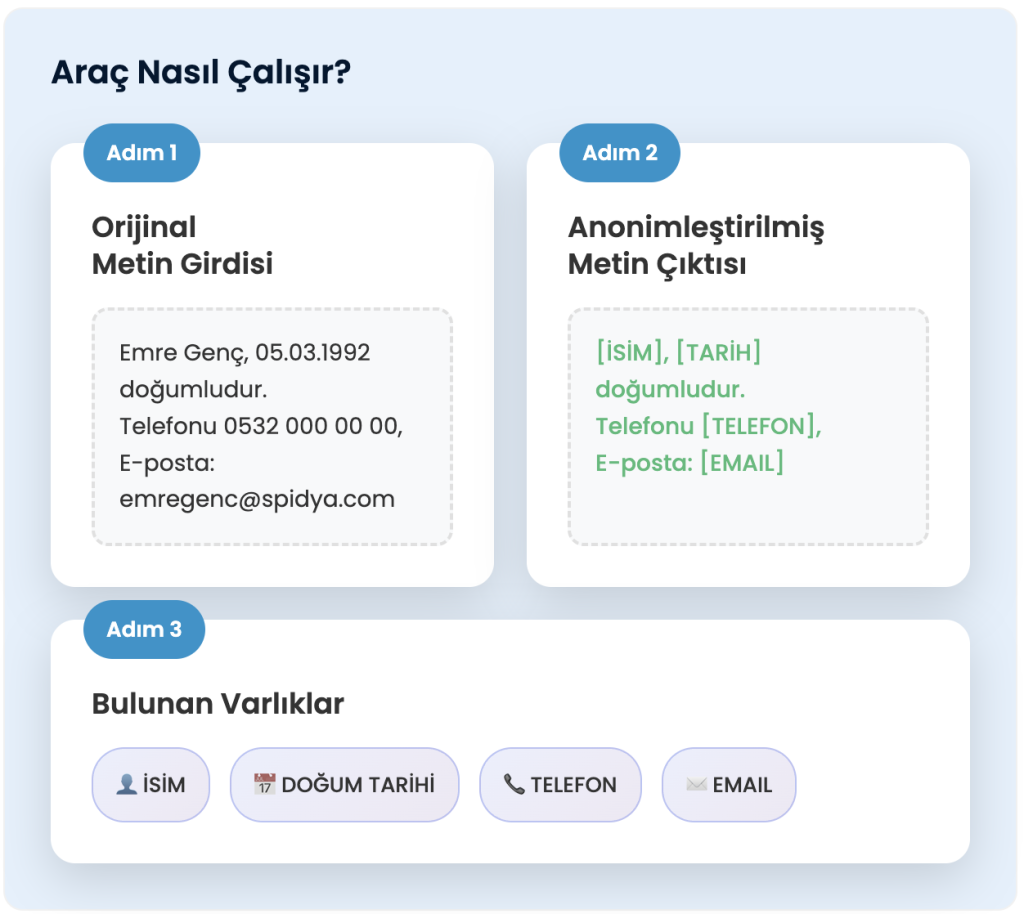
Nasıl Çalışır?
- Veriyi Girin: Metni yapıştırın veya dosya yükleyin (çeşitli formatlar desteklenir).
- Yapay Zekâ Analizi: Aracı, metindeki hassas verileri otomatik olarak tespit eder.
- Anonimleştirme: Aynı verileri tutarlı maskelerle işaretler, farklı verileri ayrı numaralarla ayırt eder.
- İndir veya Kopyala: Anonimleştirilmiş içeriği hemen indirebilir veya ihtiyacınıza göre kopyalayabilirsiniz.
Sonuç olarak…
SPIDYA’nın Veriyi Anonimleştirme Aracı, kurumların hem mevzuata uygun veri işleyişi kurmalarına hem de operasyonel riskleri minimize etmelerine yardımcı olur. Gelişmiş yapay zekâ destekli maskelenme süreçleri sayesinde, hassas verileriniz hem korunur hem de bağlamını yitirmeden işlenebilir hâle gelir, bu da dijital dönüşüm ve veri odaklı karar alma süreçlerinde önemli bir avantaj sağlar.